

- Der er blevet udtrykt mange bekymringer om, hvad den øgede adgang til kunstig intelligens kan komme til at betyde for informationssamfundet, uddannelse og endda for hele menneskeheden
- En bekymring er blandt andet, om teknologien kan fremme udbredelsen af mis- og desinformation
- Den bekymring søger den indiske virksomhed Longshot at imødegå med deres FactGPT – en slags faktatjekkende chatbot drevet af kunstig intelligens
- TjekDet har sat FactGPT på prøve, og selvom den ikke er fejlfri, giver den generelt gode resultater
- Vores forsøg med teknologien demonstrerer dog også nogle af de begrænsninger, der fortsat er ved brugen af kunstig intelligens
Skrevet af: Nathalie Damgaard Frisch, Theis Fischer Brandt og Kalle Thue Gregersen
En overflod af desinformation, en fordummet befolkning, sågar menneskehedens udryddelse.
Der er næsten ingen grænser for, hvilke dårligdomme kunstig intelligens er blevet spået at kunne føre med sig.
Særligt efter AI-chatbotten ChatGPT, der blev lanceret sidste år, gjorde kunstig intelligens til allemandseje og trak overskrifter verden over, har debatten om teknologiens implikationer fået plads på dagsordenen.
Og en af bekymringerne har altså været, at teknologien kan sætte fut under de kedler, desinformation brygges i, og øge udbredelsen af falsk information. For hvordan sikrer vi os, at den information, AI-chatbotterne serverer for os, er korrekt? Og i hvilket omfang kan teknologien anvendes til helt bevidst at producere falsk information?
De bekymringer imødekommer Longshot – en indisk virksomhed, der har skabt en AI, som efter virksomhedens eget udsagn kan lave sine egne faktatjek af selv de mest aktuelle begivenheder. Funktionen kalder de FactGPT.
Men kan FactGPT rent faktisk skelne mellem sandt og falsk? Vi har sat den på prøve. Og resultaterne er gode – men ikke fejlfrie.
Gode resultater
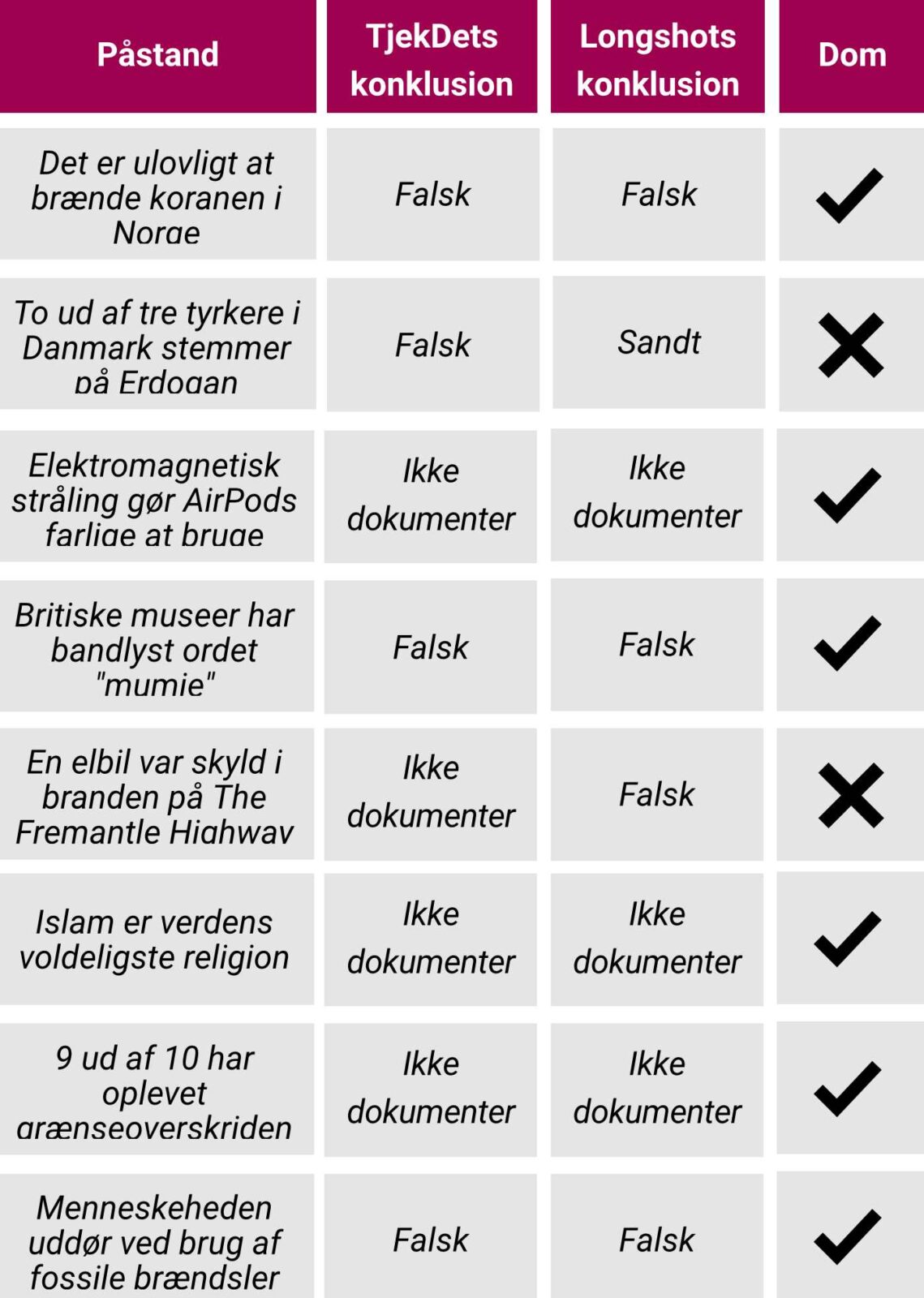
For at teste Longshots faktatjek-funktion har vi præsenteret AI’en for en række påstande, TjekDet har faktatjekket. Vi har omformuleret påstandene til spørgsmål og stillet dem til Longshots FactGPT, der herefter sammenfatter en tekst som svar.
De svar har vi sammenlignet med konklusionerne fra vores egne faktatjek, der er baseret på udtalelser fra relevante forskere, statistik fra troværdige kilder og i nogle tilfælde bare godt gammeldags gravearbejde.
Og i langt de fleste tilfælde rammer FactGPT faktisk plet.
Vi spørger den blandt andet, om det er ulovligt at brænde Koranen af i Norge, om elektromagnetisk stråling gør det farligt at bruge AirPods, om britiske museer har bandlyst ordet ‘mumie’, om islam kan karakteriseres som verdens voldeligste religion, om 9 ud af 10 har oplevet grænseoverskridende adfærd i Københavns natteliv, og om det er korrekt, at en klimaforsker har sagt, at klimaforandringerne vil udslette menneskeheden, hvis ikke vi var stoppet med at bruge fossile brændsler inden 2023. Og dens svar stemmer så godt som overens med vores egne konklusioner.
Svarene er sågar fyldt med nuancer, og der er endda kildehenvisninger. Det har den populære ChatGPT eksempelvis fået kritik for ikke at inkludere – ligesom den har fået kritik for helt at opfinde sine egne, ikke-eksisterende henvisninger.
Kun information fra særlige kilder
Blandt Longshots kilder er både faktatjekmedier, nyhedsmedier og Wikipedia.
Kilderne finder den kunstige intelligens på Google, oplyser Longshot til TjekDet. Den vælger de resultater, der dukker op først, når man laver en given søgning, og henter informationer derfra. Og så har Longshots programmører hjulpet teknologien på vej ved at pege den i retning af kilder, der ifølge virksomheden kan betragtes som troværdige, oplyser virksomheden.
Det gør, at AI’en kan finde helt nye, aktuelle informationer, og at FactGPT bruger kilder, der dels af mennesker og dels af Googles algoritme betragtes som de mest troværdige.
“Man kan sige, at vi viser AI’en et godt sted at finde information i stedet for blot at overlade det hele til den selv. Formålet er at sikre, at den kun medtager information fra kilder af høj kvalitet,” skriver den ene af Longshots stiftere, Ankur Pandy, i en mail til TjekDet.
“Chatbots har lært, at de skal være høflige og give dig et svar, som du bliver glad for”
– Luís Cruz-Filipe, lektor ved Syddansk Universitet
Men den måde at hente informationer på kan også give et bias, erkender Longshot. For søgemaskineoptimering, hvor indehavere af hjemmesider bevidst tilpasser deres indhold på en måde, så hjemmesiden opprioriteres i Googles algoritme, kan være afgørende for, hvilke resultater den kunstige intelligens medtager.
“Der er et hint af bias involveret, når man genererer indhold baseret på Googles øverste søgeresultater. Vi er klar over, at der kan være flere søgemaskineoptimerede resultater end bruger-optimerede resultater, hvilket kan gøre, at AI’en vælger irrelevante kilder,” skriver Ankur Pandy.
Men for at imødegå det problem forsøger Longshot altså at pege den kunstige intelligens i retning af det, der ifølge virksomheden er troværdige kilder. Og så medtager AI’en flere kilder for at øge informationernes troværdighed, lyder det.
Derudover er det muligt at få FactGPT til kun at hente information fra kilder, man selv uploader til platformen. Det kan være dokumenter eller andre filer, ligesom man som bruger selv kan angive webadresser eller domæner, man ønsker, AI’en skal hente information fra.
Ikke uden fejl
Men alligevel går det af og til galt. Også i de eksempler, vi testede på den.
I maj faktatjekkede vi folketingspolitiker Morten Dahlins (V) påstand om, at 67 procent af de herboende tyrkere havde stemt på den siddende præsident, Recep Tayyip Erdoğan, ved valget i Tyrkiet.
I virkeligheden var det dog blot 24 procent af tyrkerne i Danmark, som stemte på Recep Tayyip Erdoğan. Valgdeltagelsen var nemlig meget lav. Kun 41 procent af de stemmeberettigede tyrkere i Danmark brugte deres demokratiske stemme ved det tyrkiske valg. Og blandt de, der stemte, satte 58 procent kryds ved Recep Tayyip Erdoğan.
Men Longshot når til samme forkerte konklusion som Morten Dahlin.
Fejlen hos AI’en kan have sneget sig ind, fordi de 67 procent har optrådt blandt flest af de kilder, Longshot henter information fra, forklarer Luís Cruz-Filipe, der er lektor ved Syddansk Universitet, hvor han forsker i kunstig intelligens.
“Jeg vil forvente, at det er kombinationen af to ting, når den finder frem til 67 procent. Hyppigheden af, hvor mange sider tallet forekommer på, samtidig med at den muligvis har nogle interne måder, hvorpå den vurderer troværdigheden af de hjemmesider, som den finder tallet på,” siger han.
Teknologien har begrænsninger
Nøjagtig det samme skete, da vi spurgte Longshot, hvad der var årsag til branden på fragtskibet Fremantle Highway, som brød i brand ud for Hollands kyst den 25. juli.
Flere medier skrev i kølvandet på branden, at en elbil ombord på skibet var mistænkt for at være årsag. Den påstand kiggede vi for nylig nærmere på i et faktatjek. Her var vores konklusion, at årsagen til branden fortsat undersøges, og at det derfor hverken kan be- eller afkræftes, at en elbil stod bag.
Da vi spørger FactGPT, hvorvidt en elbil var skyld i branden på Fremantle Highway, giver AI’en mange korrekte oplysninger om forløbet, og i kildeafsnittet bruger den mange af de samme kilder, som vi benytter i vores faktatjek.
Men til sidst konkluderer den fejlagtigt, at branden ikke skyldtes en elbil.
“For at konkludere, så er den præcise grund til branden på Fremantle Highway ikke fastlagt, men det er blevet etableret, at det ikke var en elbil, som var ansvarlig for at starte branden,” var FactGPT’s konklusion oversat til dansk.
Og netop det tjener ifølge Luís Cruz-Filipe som et godt eksempel på, hvad kunstig intelligens som informationskilde kan på nuværende tidspunkt.
“Eksemplet viser teknologiens begrænsninger. De er gode til at finde en uhyggelig stor mængde af informationer, men de forstår ikke altid, hvad summen af information betyder. Når du beder om en konklusion, så får du et problem. For det handler også om, hvordan man stiller spørgsmålet,” forklarer Luís Cruz-Filipe og fortsætter:
“Man kan nemt komme til at tvinge den til at give et svar. Chatbots har lært, at de skal være høflige og give dig et svar, som du bliver glad for. Så hvis du spørger, om en elbil var skyld i branden, så prøver den at give dig en konklusion. Man skal prøve at stille spørgsmålene så objektivt som muligt.”
Og FactGPT’s konklusion ændrer sig da også, da vi omformulerer spørgsmålet og undlader at bruge ordet “elbil”. I stedet spørger vi: Hvilke teorier er der om årsagen til branden på Fremantle Highway?
Hertil fik vi et svar uden den fejlagtige konklusion.
Knap en uge efter – men stadig inden vores egen artikel om sagen er udgivet – stiller vi igen spørgsmålet, hvorvidt en elbil var skyld i branden, og nu undlader FactGPT at konkludere noget endeligt:
“For at konkludere, så er den præcise grund til branden fortsat ukendt, og indtil videre peger beviserne i retning af, at en elbil ikke var synderen. Efterforskningen fortsætter, og myndighederne kigger på andre muligheder, herunder på biler med forbrændingsmotorer eller en helt anden kilde,” var FactGPT’s nye konklusion oversat til dansk.
TjekDet har spurgt Longshot, hvordan det kan være, at FactGPT, som jo ellers angiveligt kun skulle give korrekte oplysninger, ikke gør det i de to tilfælde med stemmeprocenten blandt tyrkere i Danmark og branden på Fremantle Highway. Det kan der være to årsager til, lyder svaret.
“Den første er, at den tilgængelige information i første omgang var ufuldstændig eller mindre fyldestgørende. Og efter en uge var der mere information og kontekst, som gjorde AI’en i stand til at generere korrekt indhold,” skriver Ankur Pandy.
Og hvad angår antallet af tyrkere, der har stemt på Recep Tayyip Erdoğan, så kan det have været et problem, at der indgår tal i spørgsmålet.
“Det er et velkendt problem, at kunstig intelligens kan opleve visse problemer, når der er tal involveret,” skriver Ankur Pandy og fremhæver, at virksomheden forsøger at minimere den slags scenarier ved kontinuerligt at opdatere AI’ens funktioner baseret på henvendelser fra deres brugere.
Informationen bør ikke stå alene
Og det, at der kan ske fejl, er en central årsag til, at Longshot inkluderer kilder i FactGPT’s svar. På den måde kan brugerne selv dobbelttjekke svarenes sandfærdighed.
“Kilderne gør det muligt for brugerne at se, hvad AI’en har set på, inden den giver sit resultat – ligesom belægget for en påstand. Formålet er at undgå konflikter og øge transparensen, fordi brugerne på den måde kan verificere resultaterne,” skriver Ankur Pandy.
Og det er generelt en god idé at dobbelttjekke informationer, man får fra kunstig intelligens, siger Luís Cruz-Filipe. Og man bør ligeledes have øje for, at svarene, man får, kan være unuancerede.
Med de forbehold kan man godt bruge kunstig intelligens som en indledende informationskilde, vurderer han.
“Jeg vil altid råde til, at man sammenligner informationer fra kunstig intelligens med sin egen research. I udgangspunktet er kunstig intelligens en god informationskilde, så længe man forholder sig kritisk til den information, man får,” siger Luís Cruz-Filipe.
POV Overblik
Støt POV’s arbejde som uafhængigt medie og modtag POV Overblik samt dagens udvalgte tophistorier alle hverdage, direkte i din postkasse.
- Et kritisk nyhedsoverblik fra ind- og udland
- Indsigt baseret på selvstændig research
- Dagens tophistorier fra POV International
- I din indbakke alle hverdage kl. 12.00
- Betal med MobilePay
For kun 25 kr. om måneden giver du POV International mulighed for at bringe uafhængig kvalitetsjournalistik.
![]()








 og
og